![]()
Although several AI benchmarking organizations exist, MLCommons has quickly become the body that has gained the most mindshare. Its MLPerf benchmark suite covers AI training, various inference scenarios, storage, and HPC.
The organization recently released MLPerf Inference v4.1, which examines inference performance for several AI accelerators targeting datacenter and edge computing. In this research note, I attempt to give more context to the results and discuss what I consider some interesting findings.
Why Is AI Benchmarking Necessary?
Generative AI is a magical and mystical workload for many IT organizations that instinctively know there’s value in it, but aren’t entirely clear what that value is or where it applies across an organization. Yes, more traditional discriminative AI uses, such as computer vision, can deliver direct benefits in specific deployments. However, GenAI can have far broader applicability across an organization, though those use cases and deployment models are sometimes not as obvious.
Just as AI is known yet unfamiliar to many organizations, learning what comprises the right AI computing environment is even more confusing for many of them. If I train, tune, and use, let’s say, Llama 3.1 across my organization for multiple purposes, how do I know what that operating environment looks like? What is the best accelerator for training? What about when I integrate this trained model into my workflows and business applications? Are all inference accelerators pretty much the same? If I train on, say, NVIDIA GPUs, do I also need to deploy NVIDIA chips for inference?
Enterprise IT and business units grapple with these and about 82 other questions as they start to plan their AI projects. The answer to each question is highly dependent on a number of factors, including (but not limited to) performance requirements, deployment scenarios, cost, and power.
If you listen to the players in the market, you will quickly realize that each vendor—AMD, Cerebras, Intel, NVIDIA, and others—is the absolute best platform for training and inference. Regardless of your requirements, each of these vendors claims supremacy. Further, each vendor will happily supply its own performance numbers to show just how apparent its supremacy is.
And this is why benchmarking exists. MLCommons and others make an honest attempt to provide an unbiased view of AI across the lifecycle. And they do so across different deployment types and performance metrics.
What Is in MLPerf Inference v4.1?
MLPerf Inference v4.1 takes a unique approach to inference benchmarking in an attempt to be more representative of the diverse use of AI across the enterprise. AI has many uses, from developers writing code to business analysts tasked with forecasting to sales and support organizations providing customer service. Because of this, many organizations employ mixture of expert (MoE) models. An MoE essentially consists of multiple, smaller, gated expert models that are invoked as necessary. So, if natural language processing is required, the gate activates the NLP expert. Likewise for anomaly detection, computer vision, etc.
In addition to its traditional testing of different inference scenarios, the MLPerf team selected Mistral’s Mixtral 8x7B as its MoE model for use in v4.1. This enables testing that demonstrates the broader applicability of inference across the enterprise. In Mixtral, the MLPerf team chose to test against three tasks in particular: Q&A (powered by the Open Orca dataset), math reasoning (powered by the GSM8K dataset), and coding (powered by the MBXP dataset).
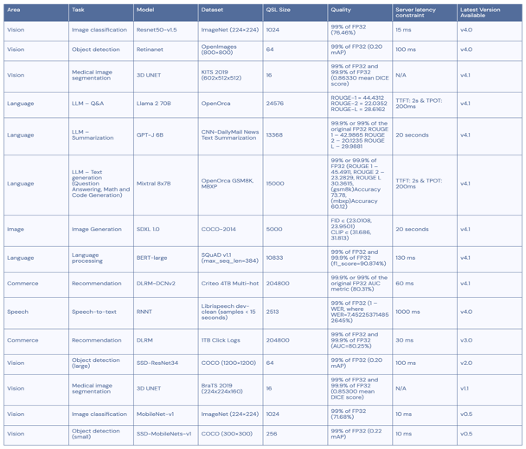
As seen in the table below, MLPerf Inference v4.1 looks at inferencing scenarios that span uses across the enterprise, with tests that show variances for latency and accuracy.
Performing a Benchmark and Checking It Twice
There are a couple of other things worth mentioning related to MLPerf that I believe show why it’s a credible benchmark. First, all results are reviewed by a committee, which includes other submitters. For example, when AMD submits testing results for its MI300, NVIDIA can review and raise objections (if applicable). Likewise, when NVIDIA submits its results, other contributing companies can review and object as they see fit.
Additionally, chip vendors can only submit silicon that is either released or will be generally available within six months of submission. This leads to results that are more grounded in reality—either what’s already on the truck or what will be on the truck shortly.
For this benchmark, AMD, Google, Intel, NVIDIA, and UntetherAI were the chips evaluated by 22 contributors from server vendors, cloud providers, and other platform companies. Chips from Qualcomm, Cerebras, Groq, and AWS were surprisingly absent from the sample. It is also important to note that while Intel submitted its “Granite Rapids” Xeon 6 chip for testing, its Gaudi accelerator was not submitted.
There are many reasons why an organization might not submit. It could be resource constraints, cost, or a number of other reasons. The point is, we shouldn’t read too much into a company’s choice to not submit—other than that there’s no comparative performance measurement for the chips that weren’t submitted.
One final consideration when reviewing, if you choose to review the results on your own: not every test was run on every system. For instance, when looking at the inference datacenter results, NeuralMagic submitted results for the NVIDIA L40S running in the Crusoe Cloud for Llama 2-70B (Q&A). This was the only test (out of 14) run. So, use the table above to decide what kind of testing you would like to review (image recognition, language processing, medical imaging, etc.) and the configuration you’d like (number of accelerators, processor type, etc.) to be sure you are looking at relevant results. Otherwise, the numbers will have no meaning.
What Can We Take Away from the Results?
If appropriately used, MLPerf Inference v4.1 can be quite telling. However, it would likely be unfair for me to summarize the results based on what I’ve reviewed. Why? Precisely because there are so many different scenarios by which we can measure which chip is “best” in terms of performance. Raw performance versus cost versus power consumption are just a few of the factors.
I strongly recommend visiting the MLCommons site and reviewing your inference benchmark of choice (datacenter versus edge). Further, take advantage of the Tableau option at the bottom of each results table to create a filter that displays what is relevant to you. Otherwise, the data becomes overwhelming.
While it is impossible to provide a detailed analysis of all 14 tests in datacenter inference and all six tests in edge inference, I can give some quick thoughts on both. On the datacenter front, NVIDIA appears to dominate. When looking at the eight H200 accelerators versus eight AMD MI300X accelerators in an offline scenario, the tokens/second for Llama 2-70B (the only test submitted for the MI300X) showed a sizable advantage for NVIDIA (34,864 tokens/second versus 24,109 tokens/second). Bear in mind that this comparison does not account for performance per dollar or performance per watt—this is simply a raw performance comparison.
When looking at NVIDIA’s B200 (in preview), the performance delta is even more significant, with offline performance coming in at 11,264 tokens/second versus 3,062 tokens/second for the MI300X. Interestingly, this performance advantage is realized despite the B200 shipping with less high bandwidth memory (HBM).
When looking at inference on the edge, UntetherAI’s speedAI240 is worth considering. The company submitted test results for resnet (vision/image recognition), and its numbers relative to the NVIDIA L40S are stunning in terms of latency, with the speedAI 240 coming in at .12ms and the L40S coming in at .33ms for a single stream. It’s worth noting that the speedAI 240 has a TDP of 75 watts, and the L40S has a TDP of 350 watts.
The work of the MLCommons team yields many more interesting results, which are certainly worth investigating if you are scoping an AI project. One thing I would recommend is using the published results, along with published power and pricing estimates (neither NVIDIA nor AMD publish pricing), to determine the best fit for your organization.
Navigating the Unknowns of AI
I’ve been in the IT industry longer than I care to admit. AI is undoubtedly the most complex IT initiative I’ve seen, as it is a combination of so many unknowns. One of the toughest challenges is choosing the right hardware platforms to deploy. This is especially true today, when power and budget constraints place hard limits on what can and can’t be done.
MLCommons and the MLPerf benchmarks provide a good starting point for IT organizations to determine which building blocks are best for their specific needs because they allow comparison of performance in different deployment scenarios across several workloads.
MLPerf Inference v4.1 is eye-opening because it shows what the post-training world requires, along with some of the more compelling solutions in the market to meet those requirements. While I expected NVIDIA to do quite well (which it did), AMD had a strong showing in the datacenter, and UntetherAI absolutely crushed on the edge.
Keep an eye out for the next training and inference testing round in the next six months or so. I’ll be sure to add my two cents.

















































































